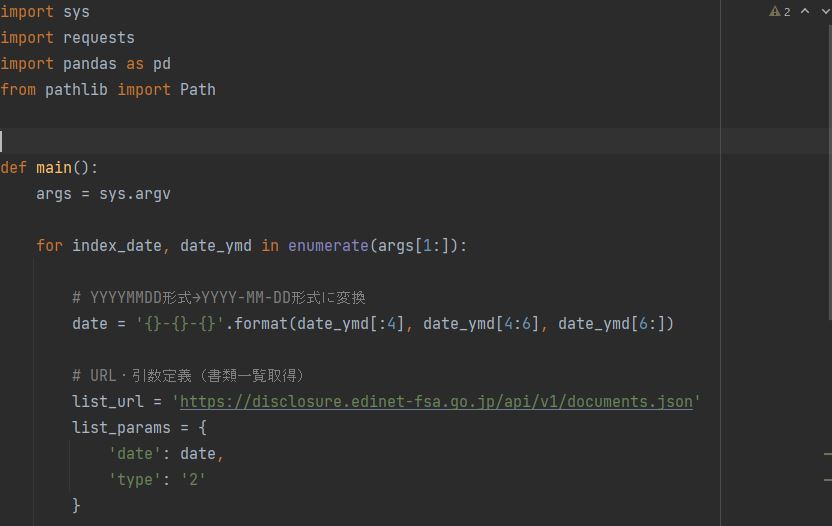
EDINETから資料(PDF、XBRL)データをダウンロードするpythonのコードです。
元々過去3年分しかデータダウンロードできなかったですが、2023年から過去10年分のデータがダウンロードできるようになりました。
2023/1/4(水)時点で2013/1/4のデータがダウンロードできました。
以下コードになります.
import sys
import requests
import pandas as pd
from pathlib import Path
def main():
args = sys.argv
for index_date, date_ymd in enumerate(args[1:]):
# YYYYMMDD形式→YYYY-MM-DD形式に変換
date = '{}-{}-{}'.format(date_ymd[:4], date_ymd[4:6], date_ymd[6:])
# URL・引数定義(書類一覧取得)
list_url = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents.json'
list_params = {
'date': date,
'type': '2'
}
# ファイル一覧をEDINETから取得
doc_list = requests.get(list_url, list_params).json()
df = pd.DataFrame(doc_list['results'])
count = len(doc_list['results'])
# print("{}処理件数:{}件".format(date, len(doc_list['results'])))
# ファイル一覧をCSV形式で保存
list_path = "./edinet_doc/list/"
list_file = "doc_list_{}.csv".format(date_ymd)
Path(list_path).mkdir(parents=True, exist_ok=True)
df.to_csv("{}/{}".format(list_path, list_file), encoding='utf_8_sig')
for index_doc, row in df.iterrows():
print("{} : {}/{}".format(date, str(index_doc + 1), str(count)))
doc_id = row['docID']
# 銘柄コード・銘柄名(提出者名)・書類名を取得
if row['secCode'] is None:
code = 'zzzz'
else:
code = str(row['secCode'])[:4]
if row['filerName'] is None:
name = 'no_name'
else:
name = row['filerName'].replace(' ', '').replace(' ', '')
if row['docDescription'] is None:
description = 'no_title'
else:
description = row['docDescription'].replace(' ', '').replace(' ', '')
# URL・引数定義(書類取得)
doc_url = "https://disclosure.edinet-fsa.go.jp/api/v1/documents/{}".format(doc_id)
pub_param = {'type': '1'}
pdf_param = {'type': '2'}
at_param = {'type': '3'}
en_param = {'type': '4'}
# 提出本文書及び監査報告書
pub_path = "./edinet_doc/xbrl/{}/".format(date_ymd)
pub_file = "{}_{}_{}.zip".format(code, name, description)
get_file(pub_path, pub_file, doc_url, pub_param)
# PDFファイル
pdf_path = "./edinet_doc/pdf/{}/".format(date_ymd)
pdf_file = "{}_{}_{}.pdf".format(code, name, description)
get_file(pdf_path, pdf_file, doc_url, pdf_param)
# 提出本文書及び監査報告書
at_path = "./edinet_doc/attach/{}/".format(date_ymd)
at_file = "{}_{}_{}.zip".format(code, name, description)
get_file(at_path, at_file, doc_url, at_param)
# 英文ファイル
en_path = "./edinet_doc/en/{}/".format(date_ymd)
en_file = "{}_{}_{}.zip".format(code, name, description)
get_file(en_path, en_file, doc_url, en_param)
# break
def get_file(path, file, url, param):
Path(path).mkdir(parents=True, exist_ok=True)
docs = requests.get(url, param)
if docs.headers['Content-Type'] != "application/json;charset=utf-8":
file = open(path + file, "wb")
file.write(docs.content)
if __name__ == "__main__":
main()



コメントを残す